Trusted AI - Natural Language Processing and Knowledge Graphs for Naval Systems Intelligence
1 Technical Approach and Justification
1.1 Overview of Approach
Identifying the complex causes of potential mission or weapon system failure (or success) and determining effective responses to preventing (or ensuring) such requires leveraging best in class machine learning techniques on rapidly growing, but often poorly structured, data. While the tools available for data science continue to evolve, there remain significant challenges for teams of decision makers trying to wrangle insight from the large and complex data accessible to them. The processes of reviewing, labeling, and classifying massive amounts of information takes extensive time, money, and human power. Fortunately, recent advances in natural language processing (NLP) and related machine learning tools such as knowledge graphs (KG) can be harnessed to gain insight and answer these critical questions. Growing availability of both open source and commercial NLP tools has made it easier for experimentation but also easier to use machine learning algorithms as “black box” tools in which data is blindly input and tool parameters tweaked to obtain the highest accuracy score. This “black box” approach introduces uncertainty (untrusted AI) which could lead to global inefficiencies at best and unexpected miss-classifications at worst. Our framework is being developed with the larger set of Naval Trusted AI projects administered by Crane NSWC, with an overarching focus of effort summarized in Figure 1. It will not rely upon pre-trained “black box” third party inference engines. This requires leveraging a smaller trusted training data set and capitalizing on both KG and NLP contributions to reach acceptable levels of accuracy. Additionally, we include visualizations and robustly explore the parameter tuning space.

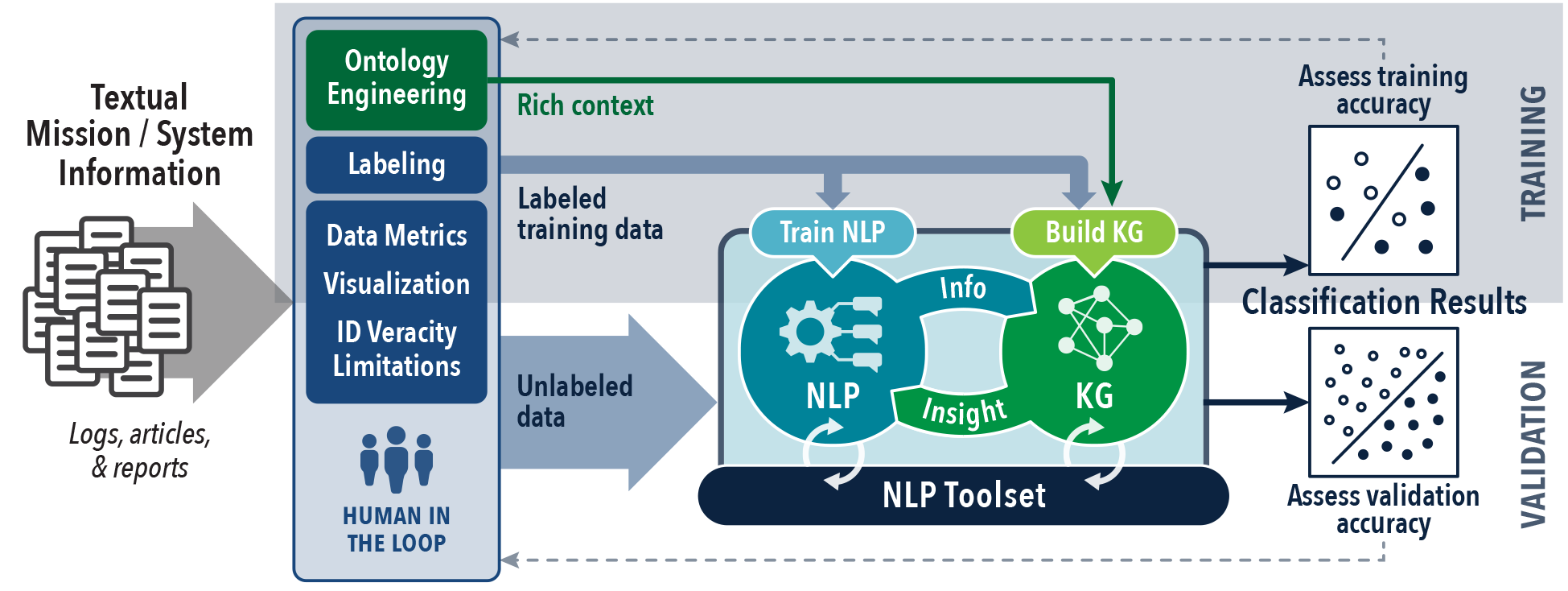
We propose a hybrid KG and NLP based solution for knowledge extraction from large volumes of textual mission/system data given relatively small volumes of labeled training articles (shown in Figure 2). Preliminary validation of this solution is being performed by ND faculty and students in collaboration with Crane NSWC on multiple large select data sets of particular importance to US Navy missions (where large represents a size impractical for rapid analysis by human readers). The framework and computational workflow are being developed in such a way that military data scientists can select appropriate components such as support vector machines (SVMs), Recurrent Neural Networks (RNNs) or bidirectional encoder representations from transformers (BERT) to classify a large corpus of text documents given a small quantity of training documents. These tools will be used to investigate automated KG construction and enrichment providing deeper context to NLP tools.
This project also includes a major workforce development component. 10 undergraduates will participate in the project for at least one semester each. Students are US citizens and it is expected that multiple students will be ROTC cadets in good standing toward becoming future military officers. Students enhance both their AI and cyber skills through interface with the project scientists and professional software engineers. They: 1) learn and leverage machine learning tools, 2) experience the veracity, volume, variety, velocity and value of big data first hand and 3) learn and demonstrate best practices in software engineering.
4 Scientific and Technical Progress
Phase 1 (Y1+3M June 2021 – September 2022) of the project delivered a hybrid KG and NLP based solution for knowledge extraction from large volumes of textual mission/system data given relatively small volumes of labeled training articles (and little to no external [untrusted] training data). Preliminary validation of this solution was performed by ND faculty and students in collaboration with Crane on multiple large maintenance data sets of particular importance to the USN (where large represents a size impractical for rapid analysis by human readers). The data science team evaluated appropriate components such as support vector machines (SVMs), Recurrent Neural Networks (RNNs) and bidirectional encoder representations from transformers (BERT) to classify a large corpus of maintenance logs given a small quantity of training documents. Given the limitations of a smaller trusted training set it was found that the SVMs provided the highest weapon subsystem classification accuracies ranging from 96% to 57% relative to the contextual differences in log event descriptions between the specific weapon subsystems. NN based classifiers leveraged pretrained open source nets such as the Hugging Face BERT NN with modestly lower accuracies than the SVMs. Given the pretrained external nets introduced additional risk (less trust) the SVMs were deemed a valid high trust option.
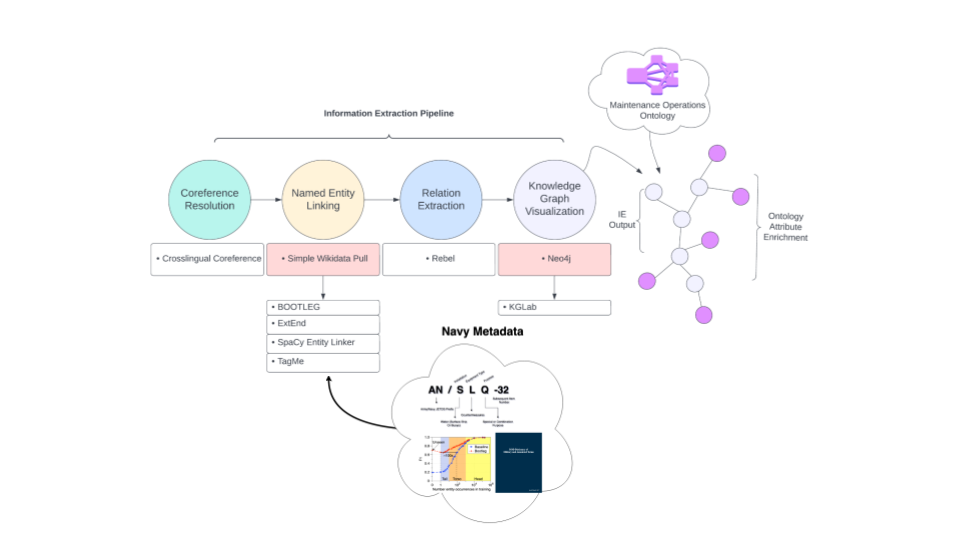
For further accuracy improvement, the team has shifted to its parallel work in KG creation and is enriching KGs with NLP based context aware tools to enrich KGs for higher accuracy weapon subsystem classification. A summary of the KG enrichment pipeline is shown in Figure 3.